
noindex and nofollow rules in links can make or break a page and how it’s indexed. Most of the time these are used together, but sometimes they are seen as interchangeable or mis-used entirely.
So, what’s the right way to use them and when?
They are both attribute settings which can be added to links to help direct crawlers. So firstly, their definitions:
What Is nofollow?
nofollow shows that a link shouldn’t be used to pass on authority or anything else for page rankings. If we use the example of links being a vote or endorsement, then the nofollow attribute takes this away or gives a null value.
It’s coded as <a rel=”nofollow” …> within a link.
What Is noindex?
noindex is an attribute set at the page level rather than link. It shows that the page it is on shouldn’t be submitted for indexing. Despite this, the page can still be crawled and links on from it can be followed too.
It’s coded in the head of the page as <meta name=”robots” content=”noindex”>
When To Use Them?
There are many instances where either or both of these would be used, but in generally they are applied to pages which you don’t want to be indexed or to pass on authority. These include staging sites, pages you want to be slightly more private or alternative versions to avoid duplication.
There are nuances to their usage though and this often leads to misuse. I’ll go through them in more detail below.
When To Use nofollow
nofollow is more to do with spam and controlling the amount of crawled links to and from sites. This helps avoid potential penalties by controlling the amount of links between pages.
This won’t stop pages being indexed in any way, so this shouldn’t be seen as protection against being indexed.
Usage Examples
If you have an affiliate website which you link to often – such as in a footer if you developed a site, a sister company or advertising partner. In this case you won’t want each instance to be counted, as you’ll end up with thousands of links from one domain to another, which can potentially cause spam issues.
The user will want to see and use these links though, so this nofollow attribute allows a user to do so whilst stopping crawlers from counting every link.
Another example is to control the paths which crawlers take – although this only works for certain crawlers depending on how they honour nofollow.
With the example of Google, the crawler won’t follow the link through to the target URL either, so if you want crawlers to go from your header links rather than body content links, then you can add nofollow to the body links in question. This is a niche usage, but it can be required on bigger, more complex sites. See the table below for information on how crawlers interact with nofollow.
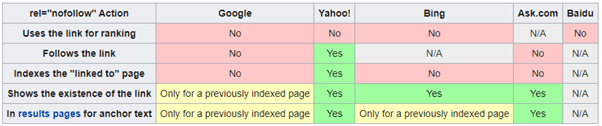
When To Use noindex
noindex is arguably simpler, but not without intricacies. If a page has the noindex tag in the header, then the page should not be indexed by search engines – such as on staging and development sites.
This is often used in conjunction with a disallow directive in the robots.txt file to make sure that these pages are not accessible through Google’s index.
Usage Examples
As mentioned, the most frequent implementation is on staging sites to make sure that these temporary URLs aren’t seen.
This can also fall under duplication, which is another big example. Archives, printer friendly versions and other duplicates can be set to noindex to make sure that one page gets the authority and is visible to searchers.
Caveats
As with all things SEO there are multiple routes and methods to use. Below are a few examples of caveats and instances where these attributes might not be as straightforward as they seem.
Other Crawlers
Not all crawlers are equal and although Google or Bing may honour a certain directive, it doesn’t mean others will. If you really don’t want something to be indexed, then don’t make it public. Other crawlers can completely ignore all these directives.
Alternatives And Canonicals
Having a noindex tag due to alternative URLs is fine, but there are often other ways to handle them. If you have a duplicate page due to languages, then a hreflang tag is needed. Similarly, if you have alternatives due to slightly differing content, then a canonical tags may make the best of your situation.
Directives Being Ignored
noindex is sometimes ignored and you might see things in Google Search Console such as “Indexed, though blocked by ‘noindex’ tag”. This basically means that despite the noindex tag, Google deems it worthy of index for whatever reason. In this case you’ll need to look into alternatives or possibly removing the noindex tag from that page to make it more straightforward.
If you’re not sure, don’t make assumptions and do what you think is best. Get in touch with us and discuss specific SEO services tailored to your needs.
