
An important, but sometimes overlooked element of technical SEO strategy is the robots.txt file. This file alone, usually weighing not more than a few bytes, can be responsible for making or breaking your site’s relationship with the search engines.
Robots.txt is often found in your site’s root directory and exists to regulate the bots that crawl your site. This is where you can grant or deny permission to all or some specific search engine robots to access certain pages or your site as a whole. The standard for this file was developed in 1994 and is known as the Robots Exclusion Standard or Robots Exclusion Protocol. Detailed info about the robots.txt protocol can be found at robotstxt.org.
Standard robots.txt Rules
The “standards” of the Robots Exclusion Standard are pretty loose as there is no official ruling body of this protocol. However, the most widely used robots elements are:
– User-agent (referring to the specific bots the rules apply to)
– Disallow (referring to the site areas the bot specified by the user-agent is not supposed to crawl – sometimes “Allow” is used instead of it or in addition to it, with the opposite meaning)
Often the robots.txt file also mentions the location of the sitemap.
Most existing robots (including those belonging to the main search engines) “understand” the above elements, however not all of them respect them and abide by these rules. Sometimes, certain caveats apply, such as this one mentioned by Google here:
While Google won’t crawl or index the content of pages blocked by robots.txt, we may still index the URLs if we find them on other pages on the web. As a result, the URL of the page and, potentially, other publicly available information such as anchor text in links to the site, or the title from the Open Directory Project (www.dmoz.org), can appear in Google search results.
Interestingly, today Google is showing a new message:
“A description for this result is not available because of this site’s robots.txt – learn more. “
Which further indicates that Google can still index other pages even if they are blocked in a Robots.txt file.
File Structure
The typical structure of a robots.txt file is something like:
User-agent: *
Disallow:
Sitemap: https://www.yoursite.com/sitemap.xml
The above example means that any bot can access anything on the site and the sitemap is located at https://www.yoursite.com/sitemap.xml. The wildcard (*) means that the rule applies to all robots.
Access Rules
To set access rules for a specific robot, e.g. Googlebot, the user-agent needs to be defined accordingly:
User-agent: Googlebot
Disallow:/images/
In the above example, Googlebot is denied access to the /images/ folder of a site. Additionally, a specific rule can be set to explicitly disallow access to all files within a folder:
Disallow:/images/*
The wildcard in this case refers to all files within the folder. But robots.txt can be even more flexible and define access rules for a specific page:
Disallow:/blog/readme.txt
– or a certain filetype:
Disallow:/content/*.pdf
Similarly, if a site uses parameters in URLs and they result in pages with duplicate content you can opt out of indexing them by using a corresponding rule, something like:
Disallow: /*?*
(meaning “do not crawl any URLs with ? in them”, which is often the way parameters are included in URLs).
That’s quite an extensive set of commands with a lot of different options. No wonder, then, that often site owners and webmasters cannot get it all right, and make all kinds of (sometimes dangerous or costly) mistakes.
Common robots.txt Mistakes
Here are some typical robots.txt mistakes:
No robots.txt file at all
Having no robots.txt file for your site means it is completely open for any spider to crawl. If you have a simple 5-page static site with nothing to hide this may not be an issue at all, but since it’s 2012, your site is most likely running on some sort of a CMS. Unless it’s an absolutely perfect CMS (and I’m yet to see one), chances are there are indexable instances of duplicate content because of the same articles being accessible via different URLs, as well as backend bits and pieces not intended for your site visitors to see.
Empty robots.txt
This is just as bad as not having the robots.txt file at all. Besides the unpleasant effects mentioned above, depending on the CMS used on the site, both cases also bear a risk of URLs like this one getting indexed:
https://www.somedomain.com/srgoogle/?utm_source=google&utm_content=some%20bad%20keyword&utm_term=&utm_campaign…
This can expose your site to potentially being indexed in the context of a bad neighbourhood (the actual domain name has of course been replaced but the domain where I have noticed this specific type of URLs being indexable had an empty robots.txt file)
Default robots.txt allowing to access everything
I am talking about the robots.txt file like this:
User-agent: *
Allow:/
Or like this:
User-agent: *
Disallow:
Just like in the previous two cases, you are leaving your site completely unprotected and there is little point in having a robots.txt file like this at all, unless, again, you are running a static 5-page site á la 1998 and there is nothing to hide on your server.
Using robots.txt to block access to sensitive areas of your site
If you have any areas on your site that should not be accessible, password protect them. Do not, I repeat, DO NOT ever use robots.txt for blocking access to them. There are a number of reasons why this should never be done:
- robots.txt is a recommendation, not a mandatory set of rules;
- Rogue bots not respecting the robots protocol and humans can still access the disallowed areas;
- robots.txt itself is a publicly accessible file and everybody can see if you are trying to hide something if you place it under a disallow rule in robots.txt;
- If something needs to stay completely private do not put it online, period.
Disallow All
Ask any SEO professional what their worst nightmare is, and they’ll most say; ‘coming into work on Monday to find the robots.txt file configured like this;
User-agent: *
Disallow: /
This means that all search engines (and any bots that obey the file) are not permitted to crawl any page on the site.
While some site owners do this intentionally, this is a fairly common mistake that can happen for a number of reasons (for example, if you have staging site that you’re blocking, and then accidently port all the settings over to the new, live site). Corona, the beer brand, are doing this right now;
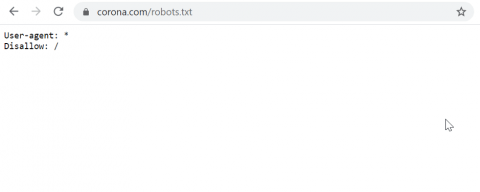
This mistake can be potentially disastrous for a site that relies heavily on organic traffic to generate revenue or leads, because blocking the entire site will often lead to the pages very quickly plummeting in the search results.
Google won’t necessarily take the pages out of the index, but because its being instructed not to crawl, often no meta description will appear. Google won’t be crawling any of the content on the site, so won’t be able to match user queries back to the topic of the pages, hence the ranking drop.
Luckily, there are ways to fairly rapidly spot such mistakes these days. Google’s coverage report in search console flags up any increases in blocked pages (see below).
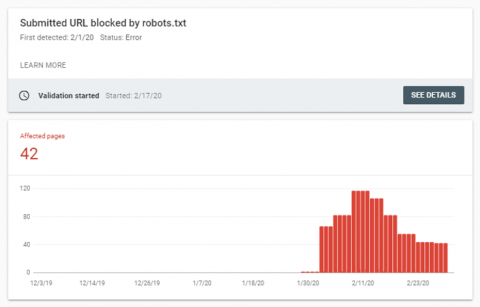
If you need to keep an even closer eye on your robots.txt file, tools like Little Warden can be configured to email you an alert if anything in your file changes, which means if you do get any nasty surprises, you can act on them as quickly as possible.
Disallowing Entire Directories
You may have a good reason for disallowing an entire directory, and if that’s the case, carry on, but in many instances there may be single pages within that directory that you need search engines to be able to crawl.
This is a crude example, but let’s say you have a clothing site selling winter coats. It’s summer, so you don’t want any of your winter coats pages being crawled or indexed, but there’s one product that falls under the winter coats directory; let’s say is the Poncho, which is popular with summer festival goers (for protecting themselves against the inevitable downpour!), you’d want allow that page to be crawled, even though you’re blocking the directory it sits on. It might go something like this;
User-agent: *
Disallow: /winter-coats
Allow: /winter-coats/poncho
N.B. If you do have a site selling winter coats, I’m certainly not suggesting you block those products because they’re not in season, this is purely an illustrative example!
Disallowing JS and CCS
As time goes on, more and more websites are using JavaScript frameworks to present content to users and search engines.
JavaScript can come with its own problems when it comes to Organic search performance, but that’s a story for another day.
If you have a website that does rely on JS to display crucial elements of the content (and CCS, as is the case with many websites), those files should not be blocked in the robots.txt file. If they are, search engines may have problems rendering the page.
Rendering can be checked using the Mobile Friendly Testing Tool, and any errors will be displayed like so;
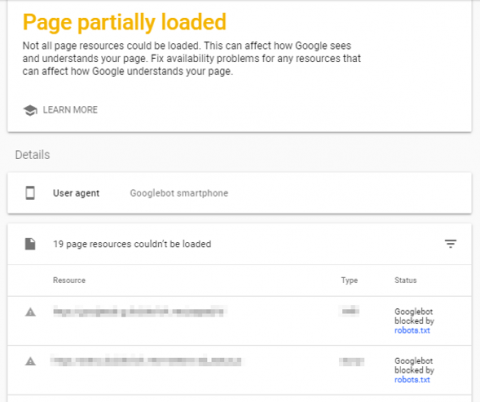
Google will tell you which resources may potentially be impeding the rendering of the page.
Not Testing Changes
Google have a robots.txt testing tool. Use it!
If there’s a particular directory or page you want to block, you can add a line to the Robots.txt Testing Tool, then check if it’s having the desired effect.
Similarly, if you are looking to block a specific directory, and want to be safe in the knowledge that it’s not going to block one of your important pages, you can check that too (see below).
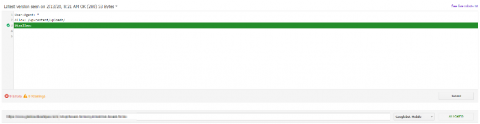
Merkle also have a pretty nifty robots.txt testing tool.
Using Robots.txt To No-Index Pages
One common misconception in SEO is that the robots.txt file can be used to ‘block’ pages from being indexed in search engines (i.e. appearing the search results), this isn’t the case, rather, the robots.txt file should be used to stop pages being crawled.
Regardless of whether or not pages being crawled, they will likely remain in the index unless the site owner specifically provides a directive to search engines telling them not to index the pages (i.e. a no-index tag).
Once the desired pages have been removed from the index, they can then be added to the robots.txt file to ensure they’re no longer crawled.
Blocking Indexed Pages
This relates very closely to the point above (I wasn’t just trying to get the list up to 10, honest), but it also applies to mistakenly blocking pages that you want to be indexed.
Luckily, Google now inform you via the coverage report in Search Console if you’ve submitted a blocked page for indexation through the XML sitemap (see below):
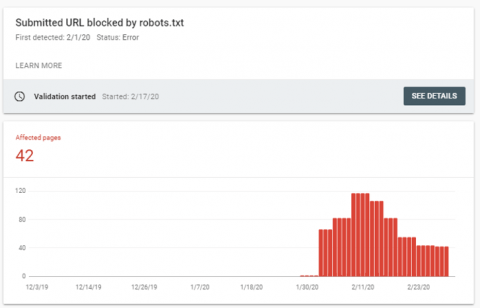
Robots.txt Bants
Although your robots.txt is a serious file that should be heavily scrutinised and checked regularly because getting it wrong can have such a negative impact on your organic performance, there’s no reason to say you can’t have some fun with it.
For example, check out Nike’s robots.txt; just crawl it!
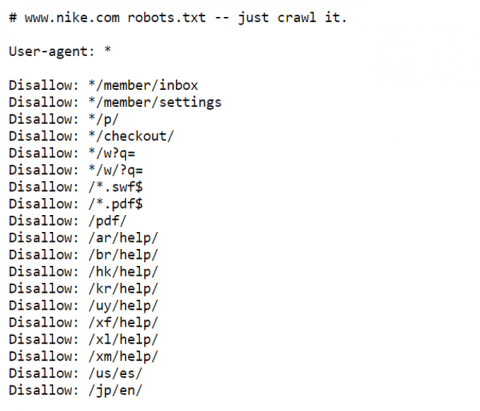
A nice piece of branding in a very functional, utilitarian area of the site, which by the way, has actually picked up 55 referring domains;
As well as making sure everything is present and correct, it might be worth getting creative with your robots.txt!
Leave a Reply